Building a UDP Token Bucket Rate Limit Server

If I have seen further than others, it is by standing upon the shoulders of giants.
, Isaac Newton
20 Apr 2017
Introduction
An earlier article, Creating a Finite State Php Rate Limiter, shows how to build a php rate limiter using mariadb database. This article describes the implementation of a UDP server that serves out tokens for individual IPv4 addresses based on Token Bucket algorithm; offering better performance than the previous rate limiter. The buckets are stored in memory, enabling faster access compared to the mariadb solution. Web applications and scripts can query the udp server for tokens to throttle and rate limit requests based on client IP addresses.
Goals and Rationale
The original php rate limiter has several weaknesses that can be improved upon. It uses a simple counter approach to limit the rate of access and relies on a mariadb database for storing the tracking counters. The use of a DBMS (database management system) has an impact on performance and resource usage. A rate limiter doesn't need all the features of a database and for our purpose, doesn't need persistent disk storage. The rate counters can be stored directly in memory.
The counter approach to rate limiting while simple doesn't offer smooth and regular throttling. Suppose we use a counter with a limit of 60 requests per minute, if 60 accesses arrive in the first second of the minute, the counter will be full after the first second. For the rest of the 59 seconds, no access is allowed. This can lead to spikes in the throttling where accesses are clustered together at the beginning of an interval. The use of token bucket algorithm can help to smooth this out, allowing a more regular throttling.
There is room to improve the original php rate limiter. A faster and more efficient system that uses memory for storage as well as the token bucket algorithm can be built.
Brief Description of Token Bucket Algorithm
Wikipedia provides a good description of Token Bucket algorithm. Briefly, we can think of a bucket with a specific capacity that stores tokens. The tokens can be used to grant access for a particular resource and is used up when granting access. The tokens are refilled at a constant rate, any excess tokens beyond the bucket capacity are discarded. Initially when the bucket is full, the consumption of tokens can be "burstable", it can serve tokens from its initial store as well as from the refilled tokens.
The "burstable" interval allows accesses beyond the refill rate and the bucket can be refilled to full capacity gradually. This allows "burstable" intervals, where the maximum rate is bounded by the bucket ( Capacity / Time interval ) + refills in Time interval. In our implementation here, we allow the bucket to be at maximum tokens capacity when rate limiting is started. As tokens are consumed from the bucket, it is gradually refilled with new tokens at a constant rate. So there will be an initial burstiness when requests arrive but subsequently it should smooth out to the rate of refill.
For example, to rate limit a web based Json API allowing a maximum of 10 calls per minute per IP address, we can first allocate a bucket with a capacity of 10 tokens to each individual IP address. Each time when an IP address calls the Json API, a token is used up from its bucket. When all tokens are used up, access will be denied. The tokens in each bucket can be refilled at a rate of 1 per 6 seconds. This refill rate means that once the initial 10 tokens are used up, the IP address will only be able to access the Json API successfully every 6 seconds, smoothing out the throttling.
The initial access is burstable as each IP bucket is given 10 tokens from the start. An IP address can make up to 20 calls in the first minute (burstable to 20), due to the 10 initial tokens and subsequent refill of 1 token every 6 seconds (10 per minute). From the second minute onwards, it will settle down to a regular rate of 1 per 6 seconds. The following diagram illustrates the Token Bucket Algorithm.

Design and Approach
A Client Server architecture can be used for this rate limiting system. The server implements the Token Bucket Algorithm and stores each IP bucket in memory. It serves out a token for each IP bucket when requested by a client, such as a web application or script. To be fast and efficient, UDP (User Datagram Protocol) will be used as the network protocol. UDP is connectionless and doesn't have the overheads of TCP (Transmission Control Protocol). We will use C to code the server for performance and to minimize resource usage.
The following diagram illustrates the architecture

In the diagram above, the client web application sends a udp message containing an IP address 192.168.25.40 to the UDP token bucket server. The server checks the IP bucket for 192.168.25.40 and the number of tokens it has. If the number of tokens is greater than zero, it is decremented by 1 and the server replies back to the client with an OK message. If the number of tokens is zero, the server will reply with a NOK message. The OK message indicates to the client that IP address 192.168.25.40 has not exceeded its allocated quota (rate limit) and the client can proceed to allow access for this request from 192.168.25.40.
The design can cater for both IP version 4 and IP version 6. However, our current implementation will only support IP version 4 for simplicity.
Components of the UDP Token Bucket Server
Using the descriptions from the earlier sections, we can construct the components for the token bucket server. A single process with multiple threads can be used to implement the UDP server. The IP buckets can be stored in a hash table for fast lookup. A separate thread can run in the background, refilling the tokens for the buckets at a regular interval. A processing thread can process client requests and response to the clients accordingly. The main thread will wait for new client requests and put these into a queue that the processing thread will pick up.
The following diagram shows the components of the UDP server. It is a single process with three separate threads: main thread, processing thread and refill thread. The multi-thread approach allows performance and scalability.

Implementing the UDP Token Bucket Server
We will organize the source code of the UDP server into a number of files. The following lists the files.
ip4bucket.c
hashtable.c
queue.c
bucketserver.c
ratelimit.h is the header file containing the declarations of function prototypes, global structures such as the ip4bucket structure, the queue structure and the rate limiting parameters etc... It is included by all the other source files.
ip4bucket.c contains helper functions for managing ip4bucket structure. It contains a function to parse IPv4 address into an integer representation that can serve as the key for the hash table, enabling fast lookup of bucket entries.
hashtable.c contains the functions for the hash table: insertion, removal and retrieval of ip4bucket hash entries.
queue.c contains the functions for the queue implementation.
bucketserver.c contains the main function and the code for the individual threads.
The full source code is available at the Github link at the bottom of the article. We will run through some of the code for the key aspects of the UDP token bucket server implementation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | ratelimit.h
/*
IP Bucket structure
The first member ipv4
serves as the key for the hash
table that is used later.
count and addr are considered
as the actual hash data
*/
struct ip4bucket
{
unsigned int ipv4;
int count;
char addr[IP4_CHAR_LEN];
};
|
The snippet above lists the ip4bucket structure. It stores an unsigned int for the integral representation of the IPv4 address, a count to track the number of tokens available and the IPv4 string. The unsigned int, ipv4, is the key for the hash table and the other two members of the struct can be considered as the hash data (value of the hash table). The function parseIP4() in ip4bucket.c is used to obtain the unsigned integer value of an IPv4 string.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | ip4bucket.c
/*
Parses an ipv4 string into
its integer representation
Takes a string containing the ipv4
string as parameter.
Returns 0 if the ipv4 string is
not valid. Returns unsigned int representation
of the ipv4 string if successful.
*/
unsigned int parseIP4(const char * p)
{
char octets[4][4];
size_t octnum=0 , index=0, i;
char c;
int val;
unsigned int ret;
while(*p != '\0')
{
c=*p;
switch(c)
{
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
octets[octnum][index] = c;
index++;
if(index == 4) // Invalid, each ipv4 octet max 3 digit
{
fprintf(stderr,"More digits than allowed %c\n", c);
return 0;
}
break;
case '.':
if(index == 0)
{
fprintf(stderr,"Empty octet \n");
return 0;
}
octets[octnum][index] = '\0';
octnum ++;
index = 0;
if(octnum == 4) // Invalid each ipv4 max 4 octets
{
fprintf(stderr,"More octets than allowed %c\n", c);
return 0;
}
break;
default:
fprintf(stderr, "Invalid character %c\n", c);
return 0; //Invalid format/char for ipv4
}
p++;
}
if( !(octnum == 3 && index > 0) )
{
fprintf(stderr, "Less than 4 octets\n");
return 0;
}
octets[octnum][index] = '\0';
ret = 0;
for(i=0;i<4;i++)
{
val = atoi(octets[i]);
if(val > 255 || val < 0 )
{
fprintf(stderr, "Value not allowed for ipv4 octet\n");
return 0;
}
ret = ret | val ;
if(i<3)
ret = ret << 8;
}
return ret;
}
|
Notice that the function returns 0 if it determines that a string is not a valid IP address format. It expects an IPv4 string to be in the standard 4 octets format ddd.ddd.ddd.ddd, where d is a digit. An octet needs a minimal of 1 digit. The function returns the unsigned integer value of the 32 bit ip address if the format is valid. It returns 0 if the format is invalid.
Note, the function will return 0 for IP address 0.0.0.0 where the 32 bit integer value is 0. Callers of the function will interpret 0.0.0.0 as invalid. Remote clients shouldn't be sending queries for 0.0.0.0. In networking, the address 0.0.0.0 generally means any IP addresses.
The unsigned integer representation returned by parseIP4() function is used as the key for the hash table. The hash table itself is just an array of ip4bucket structure. We use double hashing to implement an open addressed hash table. This is to keep the hash table at a fixed size and memory for the entire hash table is allocated directly as an array. The following code snippet shows the double hashing functions that will create the hash value from the IPv4 key. This hash value is used as the index into the array of ip4bucket structure.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | hashtable.c
#include "ratelimit.h"
static struct ip4bucket ht[HASHSZ];
static size_t hashsize;
/* hash lock for hash structure */
static pthread_mutex_t htlock = PTHREAD_MUTEX_INITIALIZER;
/* hash data lock for the data itself */
pthread_mutex_t ht_datalock = PTHREAD_MUTEX_INITIALIZER;
/* Auxiliary hash function 1 */
static size_t hash1(unsigned int ip)
{
size_t ret = (size_t) (ip % HASHSZ);
return ret;
}
/* Auxiliary hash function 2 */
static size_t hash2(unsigned int ip)
{
size_t ret = (size_t) ( (ip % (HASHSZ -1)) + 1) ;
return ret;
}
/*
Hash function for the key makes
use of hash function 1 and 2.
*/
static size_t hash(unsigned int ip, size_t i)
{
size_t ret = (size_t)(( hash1(ip) + i * hash2(ip) ) % HASHSZ );
return ret;
}
|
The hash function is composed of two auxilliary hash functions. Notice that there are also two locks used for the hash table, htlock and ht_datalock. In our earlier component diagram, the processing thread and the refilling thread can be accessing the hash table concurrently. The locks are required to prevent race conditions and ensure that the data is consistent.
The htlock handles the locking of the hash table structure. It is used when adding an item to the hashtable (array of ip4bucket structure), retrieving and removing an item from the hashtable. The ht_datalock is for modifications to the hash data, such as the counter value of a ip4bucket structure or the ipv4 string.
Using two seperate locks allow greater flexibility and concurrency. For example, when the processing thread is removing a hash entry, the refilling thread can still modify the data of a hash entry that it has already retrieved. To prevent deadlock situations from arising; functions that uses both locks, always follow a fixed order of locks acquisition, htlock follow by ht_datalock. Actually this is quite natural, since hash structure has to be accessed first to obtain a hash entry before modifications can be made to the data of the entry.
Refer to the hashtable.c file to view the code for the insertion, retrieval and removal of hash table entries. The full source code is available at the Github link at the bottom of the article.
The following snippet shows the queue structures.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | ratelimit.h
/* Queue Definitions*/
#define QUEUESZ 256
#define MSGSZ 64
struct queue_item
{
struct sockaddr_storage peer_addr;
socklen_t peer_addr_len;
char msg[MSGSZ];
};
struct queue
{
size_t size;
size_t front;
size_t end;
pthread_mutex_t lock;
pthread_cond_t qready;
struct queue_item qarray[QUEUESZ];
};
|
The queue is implemented as an array of queue_item. In each queue_item, storage is provided for the peer ip socket address so that the processing thread knows where to send the server response. Space is also provided for a message string. The message string holds the IP address that the client sends to the server. The processing thread will look up the hash table for this IP string, find its IP bucket entry and check whether it has enough tokens.
If there are sufficient tokens, it will decrement the current token count and then send a OK response back to the client. Upon receiving the OK response, the client will allow access to the protected resource. If the processing thread finds that the ip bucket has used up all its tokens, it will send a NOK response back to the client, telling the client to block access to the resource.
The queue structure contains 2 locks, one of them (lock) is used for synchronizing access to the queue. Both the main thread and the processing thread will be using the queue so synchronization is required. The main thread waits for new udp connections and messages from clients. Upon receiving a message, it places the messge and peer ip information into the queue. The processing thread will pick this up for processing and then reply back to the client.
The second lock is a conditional lock, to make reading from the queue blocking if the queue is empty. Thus the processing thread will block if there are no items in the queue for processing. When the main thread puts a new item into the queue, the enqueue function will signal that the queue is now non empty. The processing thread wakes up, pick up the item from the queue and continue with the processing. The enqueue function will return an error if the queue is full and new items cannot be added. The following snippet shows the enqueue and dequeue functions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | queue.c
/*
Enqueues a queue item
Takes a pointer to a queue and
the queue item as parameters.
Returns 1 if success, -1 otherwise
*/
int enqueue( struct queue * q, struct queue_item* item)
{
if(q == NULL || item == NULL)
return -1;
pthread_mutex_lock( &q->lock );
if( q->size >= QUEUESZ)
{
pthread_cond_signal(&q->qready);
pthread_mutex_unlock(&q->lock);
return -1;
}
q->size++;
q->qarray[q->end] = *item;
q->end++;
if(q->end == QUEUESZ)
q->end = 0;
pthread_mutex_unlock(&q->lock);
pthread_cond_signal(&q->qready);
return 1;
}
/*
Dequeues a queue item, blocks
if there is no data in queue
Takes a pointer to a queue
and return a pointer to a queue_item
if successful, NULL otherwise
*/
struct queue_item* dequeue(struct queue * q )
{
struct queue_item * ret=NULL;
if(q == NULL)
return NULL;
pthread_mutex_lock(&q->lock );
while(q->size == 0)
{ //conditional block when no data in queue
pthread_cond_wait(&q->qready, &q->lock);
}
q->size--;
ret = &q->qarray[q->front];
q->front++;
if(q->front == QUEUESZ)
q->front=0;
pthread_mutex_unlock(&q->lock);
return ret;
}
|
The following snippet shows the main function in bucketserver.c. It binds to localhost on port 3211 using UDP and waits for UDP queries from clients. The main function also starts the two other threads, the refilling thread and the processing thread. Then it loops forever waiting for client queries.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | bucketserver.c
int main(__attribute__((unused))int argc, __attribute__((unused))char* argv[])
{
char *LISTEN_HOST="localhost";
char *LISTEN_PORT="3211";
int serversocket;
ssize_t num;
struct sockaddr_storage peer_addr;
socklen_t peer_addr_len;
char buf[BUFSZ];
pthread_t tid1, tid2;
struct queue_item qt;
peer_addr_len=sizeof(peer_addr);
printf("Initializing queues\n");
initQueue(&input_queue);
printf("Initializing hash tables\n");
initHashTable();
printf("Creating Token Bucket Rate Processing thread \n");
if( pthread_create(&tid1, NULL, processing, (void *)&serversocket) != 0)
fprintf(stderr, "Cannot create processing thread\n");
printf("Creating Token Bucket Rate Refilling thread \n");
if( pthread_create(&tid2, NULL, update, NULL) != 0 )
fprintf(stderr, "Cannot create update thread\n");
bindSocket(LISTEN_HOST,LISTEN_PORT , &serversocket);
printf("Waiting for connections\n");
while(1)
{
num = recvfrom(serversocket, buf, BUFSZ, 0,
(struct sockaddr *) &peer_addr, &peer_addr_len);
if(num == -1)
{
perror("Network error");
fprintf(stderr, "Network error: received %zd\n", num);
continue;
}
if(num == 0)
continue;
//The expected correct message string
//should not be larger than BUFSZ
if(num < BUFSZ)
buf[num] = '\0';
else
buf[BUFSZ -1] = '\0';
qt.peer_addr = peer_addr;
qt.peer_addr_len = peer_addr_len;
strncpy(qt.msg, buf, strlen(buf) + 1);
if( enqueue(&input_queue, &qt) == -1)
fprintf(stderr, "Unable to queue message \n");
}
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
return 0;
}
|
We have run through the key aspects of the implementation. There is a potential race condition that is allowed for performance reason as it doesn't have a big impact on the rate limiting. When retrieving an ip4bucket from the hashtable, the following get() function is used.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | hashtable.c
/*
Retrieves an ip4bucket from
the hash table using the specified key.
Takes unsigned int key as parameter.
Returns the a pointer to ip4bucket
item if found, NULL otherwise.
Note there can be a potential race
condition where a caller of this function
obtains a reference to a hash item, but before
it can use the item, another thread removes
the item from the hash table.
In this case, this is not a critical issue.
We allow this since the hash item is only
meant for rate limiting. If the caller
continue to use the removed hash item to
decide whether access to a resource is within
limit, it is alright to be slightly wrong
and allow one more access.
*/
struct ip4bucket* get(unsigned int k)
{
size_t i, index;
i=0;
if(k==0)
return NULL;
pthread_mutex_lock(&htlock);
while(i < HASHSZ)
{
index = hash(k,i);
if(ht[index].ipv4 != 0 && ht[index].ipv4 == k)
{
pthread_mutex_unlock(&htlock);
return &ht[index];
}
else
{
i++;
}
}
pthread_mutex_unlock(&htlock);
return NULL;
}
|
The get() function returns a reference to the hash entry. A race condition can occur when a caller obtains this reference to the hash entry but another thread removes this entry from the hashtable before the caller can use or modify the hash data. The caller will not know that this has occured and will continue to use the hash entry.
In this case, the processing thread and the token refill thread will be accessing the hashtable. If the refill thread removes a hash entry that the processing thread has obtained a reference earlier, the processing thread will continue to make its rate limiting decision based on the removed hash entry. This can result in the procesing thread allowing an additional access or deny to a resource.
The impact of this is minimal for our rate limiting application. One additional access or deny usually don't matter. Furthermore, the window of occurence for this condition is small. We allow the potential race condition so that we can have faster and better performance. Rather than holding a single lock for the full duration of modifying the hash structure and the hash data; the hash structure and data have separate locks which are held on to for as short a time interval as possible.
Configuring and Compiling the UDP Token Bucket Server
The ratelimit.h file contains the parameters to control the throttling. There are 3 values, MAX_TOKENS define the maximum tokens for each IP bucket (IP address), TOKEN_REFILL defines the number of tokens that will be added to each IP bucket during the refill, and SLEEP_INTERVAL defines how long the refill thread will sleep between each refill. The following snippet shows this
1 2 3 4 5 6 7 8 | ratelimit.h
/* Rate definitions */
#define MAX_TOKENS 50
/* 1 token refill per 3 seconds */
#define TOKEN_REFILL 1
#define SLEEP_INTERVAL 3
|
The setting above set a maximum tokens of 50 per ip bucket and a refill rate of 1 token every 3 seconds (20 tokens per minute). The regular throttle rate here is 20 tokens per minute (assuming 1 token is used for 1 access) and has the granularity of 1 token per 3 seconds. For example, if a client uses this setting to limit a web submission form, up to 50 requests can be submitted (burstable to 50) in the initial phase and subsequently only a regular rate of 1 submission every 3 second. If the web submission stops, the tokens will be allowed to refill up to the maximum of 50.
A Makefile is provided in the Github repository for compiling the source files. The make command can be used to build the sources using the Makefile. Alternatively, gcc can be used to manually compile the UDP token bucket server.
The long command string uses many hardening and protection options in gcc and the linker, to produce a binary that is hardened for production use. Stack protection, position independent code, warning messages etc... are used. The source code can also be compiled on a FreeBSD or OpenBSD system. On FreeBSD 11, the default clang compiler can be used: replace gcc with cc. On OpenBSD, gcc is the default compiler and the above command can be run as is.
Refer to the Debian hardening wiki for more details on the hardening options that can be passed to gcc and the linker.
The compilation step above should produce a binary called tbserver. To build a 32bit binary on a 64bit machine, an additonal flag, -m32 can be added to compilation command. This option can be useful if you have a 32bit production server and wants to build a binary for it from a 64bit workstation. As a security best practice, compilers and build tools should not be installed on production servers.
Running the UDP Token Bucket Server
Upload the compiled binary, tbserver, to the target system using scp or sftp. The UDP token bucket server binds to localhost and port 3211 by default. These settings can be changed in the source code (bucketserver.c). If the server is configured to bind to a public IP, use a firewall to restrict access to authorized clients. This is to prevent remote network attacks against the UDP token bucket server. The current UDP server doesn't implement any forms of authentication and will accept all UDP messages sent to it.
For good operational security, we will use a separate user account to run the UDP server. On a ubuntu linux system, the following commands can be used to create a new user account and group for running the UDP token bucket server.
sudo useradd -d /opt/udpserver -m -u 8900 -g 8900 -s /bin/false tbuser
The following commands will copy the tbserver binary into the newly created /opt/udpserver directory. This is the home directory of the new tbuser account. A log directory is created to store logs for the UDP server. The permissions for the udpserver and log directories are set as 750 and 770 respectively, so that only the newly created tbuser and its group have access.
sudo cp tbserver /opt/udpserver
sudo mkdir /opt/udpserver/log
sudo chown tbuser: /opt/udpserver/log
sudo chmod 770 /opt/udpserver/log
To allow our own account access to the directories, add our account to the tbuser group. There is a need to log out and log in again for this change to take effect.
The newly created tbuser account is set with /bin/false as its shell. This will disable shell login. It also means we can't use su to change to the tbuser and start the UDP server. There are several workarounds for this. We can add code to daemonize the UDP server and switch privilege to tbuser or an easier approach is to simply setuid the UDP server binary to tbuser.
sudo chown tbuser: tbserver
sudo chmod 4750 tbserver
The commands above, setuid the tbserver binary to tbuser. This means when tbserver is executed, it will run under the tbuser account. Notice that the binary is set with 750 permission. This restricts the binary to be executable by the owner or its group. Since we have already added our own account to the tbuser group earlier, we have the necessary privilege to execute this binary.
To run the server, use the following command. It will run the UDP server as a background task.
The following screenshot shows the UDP server listening locally on port 3211. It is running under the tbuser account.
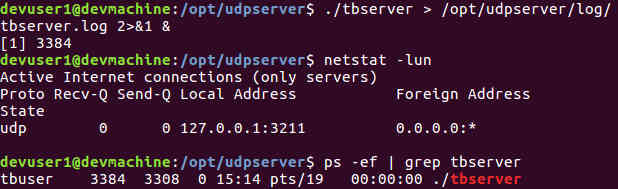
Testing the Rate Limiter
To test the UDP token bucket server, we will use the following Php script as a client that will query the UDP token bucket server for access tokens. A web server with Php support is required for running this Php script.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | <?php
/*
* MIT License
*
* Copyright (c) 2017 Ng Chiang Lin
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
/*
A token bucket throttle using a backend UDP token bucket server that
serves token.
Ng Chiang Lin
April 2017
*/
/*
Function to connect to the UDP token bucket server
and check if the remote client ip address is within
the rate limit set.
Takes the remote client ip as parameter.
Returns true if within rate, false otherwise.
*/
function checkRate($clientip)
{
$ret = $reply = $cs = false;
$cs = stream_socket_client("udp://127.0.0.1:3211", $errno, $errstr, 1);
if (!$cs)
{
error_log("Cannot open udp socket\n", 0);
return false;
}
$ret = fwrite($cs, $clientip);
if(!$ret)
{
error_log("Cannot write udp socket\n", 0);
fclose($cs);
return false;
}
$reply = fread($cs,10);
if (!$reply )
{
error_log("Cannot write udp socket\n", 0);
fclose($cs);
return false;
}
$reply = rtrim($reply);
if(strcasecmp("OK", $reply ) == 0 )
{
fclose($cs);
return true;
}
fclose($cs);
return false;
}
if( isset($_SERVER['REQUEST_METHOD']) && strcasecmp("get", $_SERVER['REQUEST_METHOD'] ) == 0 )
{
$ip = $_SERVER['REMOTE_ADDR']; //Connecting remote client ip address
header('Content-Type: text/html; charset=UTF-8');
header('Cache-control: no-store');
if(isset($_GET['ip']) && !empty($_GET['ip']))
{//Warning !
//The is only for testing, to simulate different ip
//It will not throttle real ip addresses, can be bypassed
//and lead to vulnerabilities with the throttling script
//There are also no checks for malicious input
//In Production to throttle real ip addresses,
//remove this and use $_SERVER['REMOTE_ADDR']
$ip= $_GET['ip'];
}
$ret = checkRate($ip);
if($ret)
echo "Allowed : " . $ip . "<br>\n";
else
echo "Disallowed : " .$ip . "<br>\n";
}
?>
|
Notice that the Php script takes a parameter ip, this is for stimulating different remote IP addresses during testing and should be removed in actual production code. The Php script calls the checkRate() function which sends a UDP message containing the remote IP address to the server. If the server replies with OK, it means that the remote IP address is within the rate limit. When connecting to the server, a timeout of 1 second is set for the connection. If there is no reply within 1 second, the checkRate() function will return false, indicating that access shouldn't be granted.
The Php script shows the message "Allowed: <Remote IP address>" when access is granted. It displays "Disallowed: <Remote IP address>" when the rate limit is exceeded and access is denied. The following shows a screenshot of running the Php script with a test ip parameter.
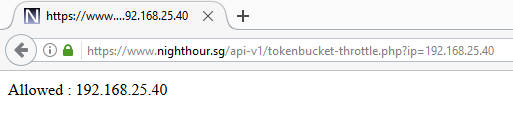
We will use a Java client to simulate multiple concurrent connections to the Php script with different IP addresses. This is the same Java client that is used in the earlier article Creating a Finite State Php Rate Limiter. We will not go through the keytool command for importing a SSL/TLS certificate if the Php web server uses SSL/TLS. Refer to the earlier article for the instructions if required.
The following shows the code snippet for the main method in the Java client. The source code of the Java Client is available at the Github link at the bottom of the article.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | public static void main(String[] args)
{
long interval = 10 * 60 * 1000;// 10 minutes
int threadmax = 50;
int totalallowed = 0;
String urls_array[] = { "https://www.nighthour.sg/api-v1/tokenbucket-throttle.php",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=10.67.190.24",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=172.100.20.212",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.7.60",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.25.40",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.30.60",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.25.164",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.121.8",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.19.6",
"https://www.nighthour.sg/api-v1/tokenbucket-throttle.php?ip=192.168.0.85" };
WebClient threads[] = new WebClient[threadmax];
for (int i = 0; i < threadmax; i++)
{
String tname = "t" + i;
int urlindex = i % urls_array.length;
String url = urls_array[urlindex];
WebClient cthread = new WebClient(tname, interval, url);
cthread.start();
threads[i] = cthread;
}
for (int i = 0; i < threadmax; i++)
{
try
{
threads[i].join();
}
catch (InterruptedException e)
{
System.err.println(e);
}
totalallowed += threads[i].getAllowed();
}
System.out.println("Total allowd for all threads is " + totalallowed);
}
|
The Java client simulates 10 different ip addresses and 50 concurrent threads accessing the Php script every second for up to 10 minutes. In the UDP token server (ratelimit.h), the default tokens configured for each IP is 50 tokens, and 1 token is added every 3 seconds (20 per minute). The total tokens per IP for 10 minutes is 50 + 20 * 10 = 250. Since there are 10 different IP addresses, the total maximum allowable access for all 10 IP addresses will be 2500.
Test Results
The following shows the result of running the Java client. A total of 2497 accesses are allowed. This is within the range of 2500 that we expect. The throttling is working properly.

Another test can be conducted for checking the regularity of the throttling. Recall that the rate limiting is now based on the Token Bucket Algorithm which offers smoother throttling. The Java Client can be modified to access the Php script using a single thread and a single IP address parameter, at a rate that matches the refill rate of the UDP token bucket rate limiter. The test result should show that access is allowed smoothly at the throttle rate. We are not doing this test in this article, it can be left as a future exercise.
Scalability
The UDP token bucket server should be able to handle much more connections than the earlier rate limiter that relies on mariadb database. The hash table is configured with a default size of 4093 (prime number) and it can stores 4093 different IP addresses. This should be enough to handle rate limiting for small personal sites. The default queue size is set to 256. The standard error and standard out of the UDP token bucket server are redirected to a log file.
The log file can provide information about queueing errors or errors adding hash entries. Such errors can indicate that parameters like the hash size or queue size need to be increased. The UDP token bucket server process uses a single processing thread and a single refill thread. For greater scalability these can potentially be increased. The single refill thread increments the tokens for all the occupied IP buckets in the hash table, each time it wakes up. The refill rate may be affected if there are many hash entries.
In this article, we only tested with 50 concurrent threads using the Java Client: a throughput of 50 requests per second. Additional testing and tuning may be required for a big site with lots of traffic to be throttled.
Hash Flooding Denial of Service Attack
An interesting attack against hash table implementation is hash flooding. What hash flooding does is to send data that hashes to the same key, this will cause the performance of the hash table to become a single linked list. Many opensource projects such as python, rust etc... have adopted siphash to mitigate such attacks.
Siphash is a efficient hashing technique optimized for short inputs that can mitigate hash flooding.
In this article, our hash implementation is actually very simple. It converts IP address into its integer representation. And this is used as the key to generate the position in the hash table through double hashing. Since the hash table size is only 4093, many different IP addresses can hash to the same location and performance degrades as probing is required.
Using Siphash will have help to mitigate this. For this article though, we keep it simple and use only the method of double hashing.
Our simple rate limiter can also be overwhelmed by denial of service attack, exhausting its resources.
Conclusion and Afterthought
A Rate Limiter can act as an additional security measure against spam bots, brute force scanners besides its usual role of resource allocation. Rate limiting can also be a measure to mitigate DDOS amplification attacks. Refer to the links below for the ACM queue article, Rate-limiting State. Rate limiting is a useful feature to implement that can enhance the security of a web application, web resource and internet infrastructure.
This article implements a rate limiter using token bucket algorithm and in-memory storage, just like Redis and Memcache. It improves upon a previous php rate limiter that relies on mariadb; offering better performance. As it is a custom simple rate limiting application that has a single purpose, many overheads are reduced. Simplicity also improves security by reducing attack surface.
The token bucket server described in this article can also be used to throttle bandwidth used for data transfer. For example, an application can map a single token to 1 kilobytes. Each token allow 1 kb of data transfer. Using the refill rate configuration of 1 token per 3 second, a kilobyte of data will be transfered every 3 second or 20 kilobytes in 1 minute for each IP address.
The UDP token bucket server is designed to be simple and fast, though it does have some weaknesses such as the inability to prevent hash flooding attack.
Stopping massive denial of service attack(DOS) or distributed denial of service attack(DDOS) are not easy and requires a totally different kind of architecture and design. The big content delivery network(CDN) uses many datacenters spread all over the world, with IP Anycast for routing and addressing.
When a DDOS occured, the attack traffic is handled as close to the source as possible and is spreaded out through the CDN. The simple application in this article will not be able to do all this.
Useful References
- Creating a Finite State Php Rate Limiter, An earlier article on php rate limiting. The current article and UDP token bucket server is meant as an improvement over the previous system.
- Beej's Guide to Network Programming, by Beej. A great tutorial on how to use network sockets using the C language.
- Debian GCC and Linker Hardening Options, Debian guide to hardening binaries.
- Token Bucket algorithm, Wikipedia's Arcticle/Description
- Rate-limiting State (The edge of the Internet is an unruly place), by Paul Vixie, Farsight Security. An ACM Queue article on how rate limiting can be used to mitigate against DDOS amplification attacks.
- SipHash, A hashing technique that can mitigate against hash flooding attack.
The source code for the UDP Token Bucket Server is available at the following Github link.
https://github.com/ngchianglin/UDPTokenBucketServer
The Php test script tokenbucket-throttle.php is available at the following Github link.
https://github.com/ngchianglin/VPS_MISC
The Java Client for testing the rate limiting can be found here
https://github.com/ngchianglin/PhpRateLimiter
If you have any feedback, comments, corrections or suggestions to improve this article. You can reach me via the contact/feedback link at the bottom of the page.
Article last updated on July 2020.